Scheduling Algorithms
FCFS (First-Come First-Served)
요청한 순서대로 처리하는 단순한 알고리즘이다. Nonpreemptive scheduling이며, 비효율적인 알고리즘이다.
Burst time이 긴 프로세스가 먼저 도착한다면, 짧은 프로세스들은 무작정 기다릴 수밖에 없다.

Time-sharing system에서 interacitve job의 응답시간이 길어지기 때문에 좋은 스케줄링 기법이 아니다.
만약 burst time이 짧은 순서대로 들어온다면,
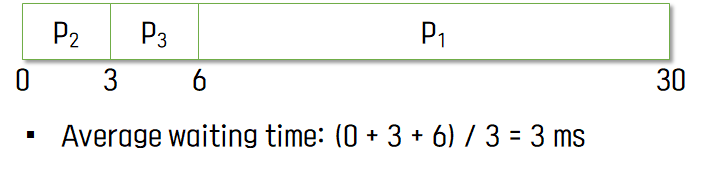
FCFS는 프로세스의 순서에 따라 waiting time에 상당한 영향을 끼친다.
문제점
-
Convoy effect이 발생한다.한 프로세스를 기다리기 위해 여러 프로세스들이 떼지어(convoy) 기다리게 되는 현상
SJF (Shortest-Job-First)
CPU Burst time이 가장 짧은 프로세스에게 CPU를 제일 먼저 할당하는 알고리즘이다. 각 프로세스의 다음번 CPU Burst time을 스케줄링에 활용한다.
이 방식은 기본적으로 Nonpreemptive한 방식이다. 일단 CPU를 잡으면 이번 CPU burst가 완료될 때까지 CPU를 선점당하지 않는다.
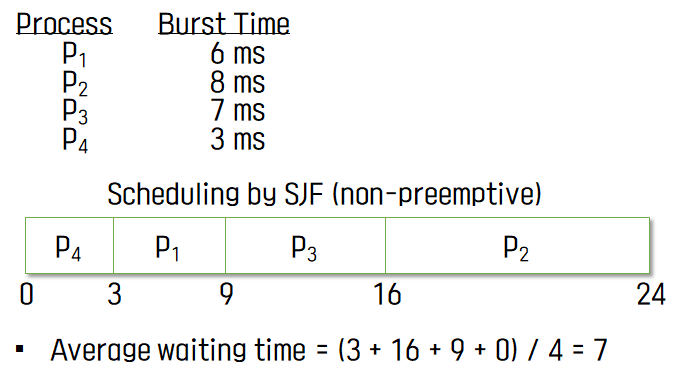
Preemptive한 방식의 경우, 현재 수행중인 프로세스의 남은 burst time보다 더 짧은 CPU burst time을 가진 프로세스가 도착하면 CPU를 빼앗긴다. 이러한 방법을 SRTF (Shortest-Remaining-Time-First) 라고도 부른다.
SRTF방법은Optimal하다. 주어진 프로세스들에 대해minimum average waiting time을 보장한다.

문제점
-
Starvation문제가 발생한다.CPU burst time이 긴 프로세스는 영원히 CPU를 할당받을 수 없는 상황(starvation)이 발생하게 된다. -
CPU burst time을 알 수 없다. 따라서 과거의 CPU 사용을 보고 예측한다.
CPU burst time 예측
과거의 CPU burst time을 이용해서 추정한다.

좀 더 똑똑하게 하려면 history 중요도가 멀어질수록(옛날 정보일수록) 가중치를 아주 급격히 낮추어서 줄 수도 있다.(exponential 하게)
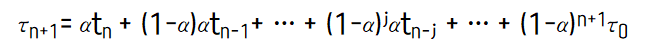
Priority Scheduling
우선순위가 제일 높은 프로세스에게 CPU를 할당하는 알고리즘이다. 정수로 우선순위를 표현하고, 작은 숫자가 우선순위가 높다는 기준을 가진다.
더 높은 우선순위를 가진 프로세스가 새로 들어오면 CPU를 넘겨주느냐/넘겨주지 않느냐에 따라 preemptive / nonpreemptive하다.
SJF도 일종의 Priority scheduling이라고 볼 수 있다.
이 방식도 마찬가지라 Starvation 문제를 가지고 있다. 낮은 우선순위의 프로세스는 영원히 실행되지 않을 수 있다. 이러한 문제점을 해결하는 방법으로 Aging이라는 기법을 사용한다.
Aging이란 우선순위가 낮은 프로세스라도 시간이 흘러감에 따라 우선순위를 높여주는 방식이다.

RR (Round Robin)
가장 현대적인 CPU Scheduling 방식이다. 각 프로세스는 동일한 크기의 할당 시간(time quantum), 일반적으로 10-100 ms을 가진다. 할당 시간이 지나면 프로세스는 선점(preemptive)당하고 Ready queue의 제일 뒤에 가서 다시 줄을 선다.
라운드 로빈의 가장 큰 장점은 응답 시간(Response time)이 짧아진다는 것이다.
n개의 프로세스가 Ready queue에 있고 할당 시간이 q time unit인 경우, 각 프로세스는 최대 q time unit단위로 CPU 시간의 1/n을 얻는다. -> 어떤 프로세스도 (n-1) q time unit이상 기다리지 않는다.
time quantum(q)를 너무 크게 잡으면 FCFS와 같은 방식이 되고,
time quantum이 너무 작아지게 되면 가장 이상적인 라운드 로빈 방식이 되겠지만, Context switch overhead가 너무 커져 컴퓨터 성능에 악영향을 끼칠 수 있다.
따라서 적당한 시간의 time quantum을 책정하는 것이 중요하다.
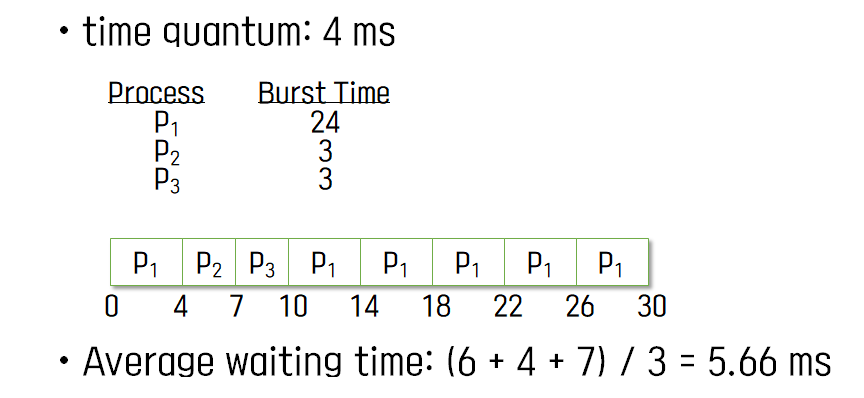
일반적으로 SJF보다 average turnaround time이 길지만 response time이 더 짧다.
Multilevel Queue
Ready queue를 여러 개의 class로 분할한다. 각각의 class마다 다른 스케줄링 알고리즘 사용이 가능하다.
e.g) 두 개의 queue
foreground (interactive한 job을 추가) - Round Robin
background (batch - no human interaction) - FCFS
interactive한 프로세스들은 우선순위가 높고, 그렇지 않은 프로세스들은 우선순위를 낮게 지정한다.
각 큐에 대한 스케줄링 또한 필요하다.
-
Fixed priority schedulingforeground에 있는 모든 프로세스를 처리하고background에 있는 프로세스에게 CPU를 할당하는 방법이다. 이 경우에는starvation문제가 발생할 수 있다. -
Time slice각 큐에
CPU time을 적절한 비율로 할당해서starvation문제를 해결할 수 있다.e.g)
foreground에 80%,background에 20% ..

Multilevel Feedback Queue
Multilevel Queue에서 프로세스가 queue들간 이동이 가능한 알고리즘이다. Aging을 이와 같은 방식으로 구현할 수 있다. e.g) 오래된 프로세스를 하위 레벨의 큐로 옮김
처음 들어오는 프로세스는 우선순위가 가장 높은 큐에 위치시켜 준다.
우선순위가 높은 큐일수록 Round Robin 기법에서 time quantum을 짧게 준다.

e.g)
- 프로세스가
Queue 0에 들어옴 Q0에 있는 프로세스가Q1의 프로세스를preempt함Q0의 프로세스가 8ms만에 끝나지 않으면,Q1의 끝에 들어감Q1의 프로세스가 16ms만에 끝나지 않으면,Q2의 끝에 들어감
Multiple-Processor Scheduling
이때까지 보았던 스케줄링은 CPU가 한 개일 때의 스케줄링 기법이다.
CPU가 여러 개인 경우, 스케줄링은 더욱 더 복잡해진다.
Homogeneous processor인 경우Queue에 한 줄로 세워서 각 프로세서가 알아서 꺼내가게 할 수 있다.- 반드시 특정 프로세서에서 수행되어야 하는 프로세스가 있는 경우에는 문제가 더 복잡해진다.
Load sharing- 일부 프로세서에
job이 몰리지 않도록 부하를 적절히 공유하는 메커니즘이 필요하다. - 별개의
queue를 두는 방법 vs. 공동queue를 사용하는 방법
- 일부 프로세서에
Symmentric Multiprocessing (SMP)- 각 프로세서가 각자 알아서 스케줄링을 결정한다.
Asymmetric multiprocessing- 하나의 프로세서가 시스템 데이터의 접근과 공유를 책임지고 나머지 프로세서는 거기에 따른다.
Real-Time Scheduling
real time job이란 데드라인이 있는 job이다. 즉, 정해진 시간 내에 반드시 처리해야 하는 job이다. 따라서 CPU scheduling을 할 때도 real time job은 데드라인을 보장해주어야 한다.
-
Hard real-time systemsHard real-time task는 정해진 시간안에 반드시 끝내도록 스케줄링해야 한다. -
Soft real-time computingSoft real-time task는 일반 프로세스에 비해 높은priority를 갖도록 해야 한다.
Tread Scheduling
-
Local SchedulingUser level thread의 경우 사용자 수준의thread library에 의해 어떤thread를 스케줄할지 결정한다. -
Global SchedulingKernel level thread의 경우 일반 프로세스와 마찬가지로 커널의 단기 스케줄러가 어떤thread를 스케줄할지 결정한다.
Algorithm Evalution
어떤 스케줄링 알고리즘이 좋은지 평가하는 기준
-
Queueing models이론적인 방법이다. 확률 분포로 주어지는
arrival rate와service rate등을 통해 각종performance index값을 계산한다. -
Implementation (구현) & Measurement (성능 측정)실제 시스템에 알고리즘을 구현하여 실제 작업
(workload)에 대해서 성능을 측정/비교한다. -
Simulation (모의 실험)알고리즘을 모의 프로그램으로 작성 후
trace를 입력으로 하여 결과를 비교한다.trace: 시뮬레이션 프로그램에 들어갈 입력 데이터를 의미한다.
본 포스팅은 이화여대 반효경 교수님의 강의와 경북대 탁병철 교수님의 강의를 토대로 작성한 글입니다.
'Computer Science > 운영체제' 카테고리의 다른 글
| [운영체제] CH6. Process Synchronization(2) (0) | 2020.08.13 |
|---|---|
| [운영체제] CH6. Process Synchronization(1) (0) | 2020.08.09 |
| [운영체제] CH5. CPU Scheduling(1) (0) | 2020.08.02 |
| [운영체제] CH4. Process Management (0) | 2020.07.30 |
| [운영체제] CH3. Process(2) (0) | 2020.07.28 |



