Java Collections Framework
Java Collections Framework란 일반적으로 재사용 가능한 컬렉션 자료 구조를 구현하는 클래스 및 인터페이스 세트이다. 자바 초기에는 Vector, Stack, Hashtable 등의 컬렉션 클래스만 제공했으나, JDK 1.2 이후 표준적인 방식으로 컬렉션을 다루기 위한 Collections Framework가 등장하였다. 모든 컬렉션 클래스 명은 구현한 인터페이스명이 포함되어 있어서 바로 클래스의 특징을 알 수 있다. 단, Vector, Stack, Hashtable처럼 JDK 1.2 이전부터 존재하던 클래스는 이러한 명명법을 따르지 않는다.
JCF의 장점
별도로 필요한 자료 구조를 구하는 것보다 이미 구현되어 있는 것을 사용함으로써 코딩 시간을 줄일 수 있다. 또한, 우리보다 훨씬 똑똑하신 형님들이 잘 만들어서 잘 테스트되고 검증되어 있기 때문에 성능을 보장한다.
[Collection Interface] - 순서나 집합적인 저장 공간
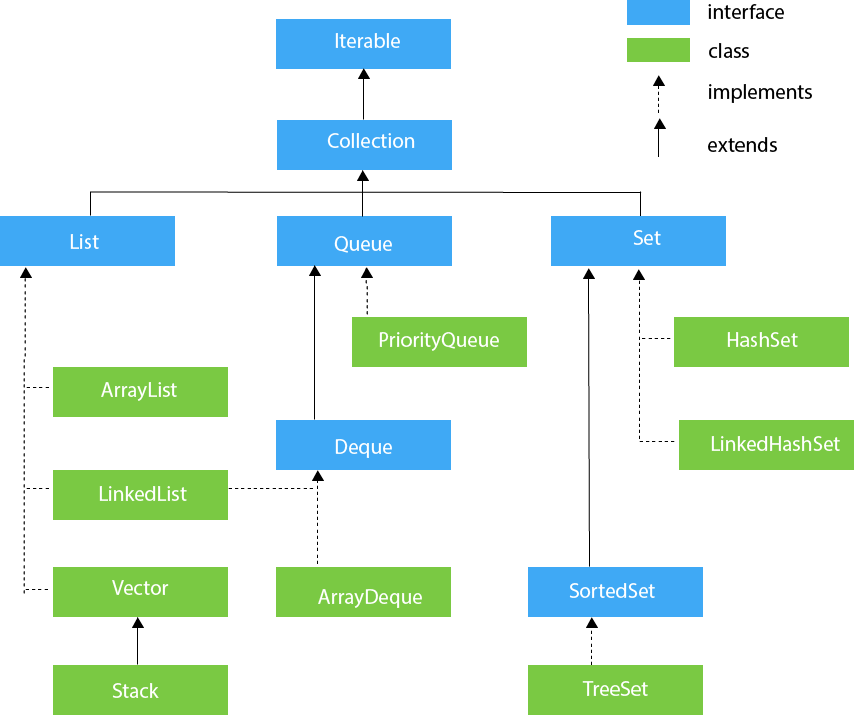
[Map Interface] - key-value 로 데이터 핸들링

컬렉션 인터페이스들은 제네릭(Generics)으로 표현되어 컴파일 시점에서 객체의 타입을 체크하기 때문에 런타임 에러를 줄이는 데 도움이 된다. 예를 들어, 런타임 시 발생하는 ClassCastException을 컴파일 시점에서 찾아낼 수 있다. 또한, 클래스 캐스팅을 하지 않아도 되고 instanceof를 사용하지 않아도 되므로 코드를 조금 더 깔끔하게 유지할 수 있다.
대표적으로 다음과 같은 세 가지 인터페이스가 존재한다.
- List
- Set
- Map
List, Set 인터페이스는 Collection 인터페이스를 상속받는다. 따라서 List 인터페이스와 Set 인터페이스의 공통된 부분을 Collection 인터페이스에서 정의하고 있다. 반면, Map 인터페이스는 구조상의 차이(Key-Value)로 인해 Collection 인터페이스를 상속받지 않고 별도로 정의되었다.
컬렉션 인터페이스를 다음과 같이 두 가지로 분류해서 살펴보자.
- Collection 인터페이스 그룹
- Map 인터페이스 그룹
1. Collections 인터페이스 그룹
[Collections 인터페이스]
Collections 인터페이스는 직접적인 구현은 제공되지 않으며, 모든 컬렉션 클래스가 구현해야 하는 메소드들을 포함하고 있다. 다음은 대표적인 메소드들이다.
- boolean add(E e): 해당 컬렉션에 전달된 요소를 추가
- boolean remove(Object o): 해당 컬렉션에서 전달된 객체를 제거
- void clear(): 해당 컬렉션의 모든 요소를 제거
- boolean contains(Object o): 해당 컬렉션이 전달된 객체를 포함하고 있는지 여부 반환
- E get(int index): 해당 인덱스에 저장된 객체를 리턴
- boolean equals(Object o): 해당 컬렉션과 전달된 객체가 같은지 여부 반환
- boolean isEmpty(): 해당 컬렉션이 비어 있는지 여부 반환
- Iterator iterator(): 해당 컬렉션의 반복자(iterator)를 반환
- int size(): 해당 컬렉션의 요소의 총 개수를 반환
- Object [] toArray(): 해당 컬렉션의 모든 요소를 Object 타입의 배열로 반환
[1.1 List 인터페이스]
List 인터페이스는 순서가 있는 컬렉션으로, 중복 요소를 포함할 수 있다. 인덱스로 모든 요소에 접근할 수 있으며, List 인터페이스로 구현된 클래스로는 ArrayList, LinkedList 가 있다.
1.1.1 ArrayList ( == Dynamic Array, C++: vector)
이름처럼 내부적으로 배열을 이용하여 데이터를 관리한다. resizable-array이면서 비동기 이다. 만약 동기화가 필요할 때는 Collections.synchronizeList() 메소드를 통해 동기화가 보장되는 List를 반환받아 사용한다.
인덱스를 가지고 있어 데이터 검색에 적합하고 속도가 빠르다.
- 시간 복잡도: O(1)
데이터의 삽입은 배열 가장 뒤에 더해진다.
- 시간 복잡도: O(1)
동기화를 지원하지 않아 vector보다 빠르다.
ArrayList는 생성자의 파라미터로 크기를 초기화할 수 있다.
{
...
List<Integer> list = new ArrayList<>(5); // 크기 5로 초기화
...
}
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
그럼 데이터가 6개 째 들어오면 어떻게 될까?
답은 grow() 메소드 안에서 호출하는 newCapacity() 메소드에 있다.
newCapacity() 메소드를 보면 capacity 범위를 넘어가는 경우 기존의 capacity의 1.5배만큼 새로운 capacity로 지정해준다.
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
private Object[] grow(int minCapacity) {
return elementData = Arrays.copyOf(elementData,
newCapacity(minCapacity));
}
private Object[] grow() {
return grow(size + 1);
}
private int newCapacity(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 기존 oldCapacity의 1.5배만큼 새로 지정
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity <= 0) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
return Math.max(DEFAULT_CAPACITY, minCapacity);
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return minCapacity;
}
return (newCapacity - MAX_ARRAY_SIZE <= 0)
? newCapacity
: hugeCapacity(minCapacity);
}
1.1.2 LinkedList
Queue, Deque 속성과 메소드를 가지고 있고 비동기이다. 내부적으로 연결 리스트를 이용하여 데이터를 관리한다.
데이터 검색 시에는 처음부터 노드를 순회하기 때문에 오래 걸리며 성능 상 좋지 않다.
- 시간 복잡도: O(n)
데이터의 삽입은 ArrayList와 마찬가지로 가장 뒤에 삽입되고, 삭제를 하기 위한 노드를 찾기 위해서는 결국 O(n)이 걸리고, 삭제를 위한 시간 복잡도까지 계산하면 결국 O(n)이 걸린다.
- 시간 복잡도: O(1)
- 만약 중간 요소의 삽입, 삭제가 없고 맨 앞과 뒤 요소의 삽입, 삭제만 한다면 O(1)이 걸린다.
| Class | add | remove | get | contains |
|---|---|---|---|---|
| ArrayList | O(1) | O(n) | O(1) | O(n) |
| LinkedList | O(1) | O(1) | O(n) | O(n) |
[1.2 Set 인터페이스]
Set 인터페이스 말 그래도 집합이라고 생각하면 된다. 중복 요소를 포함할 수 없으며, 랜덤 액세스를 허용하지 않으므로 iterator 또는 foreach를 이용하여 요소를 탐색할 수 있다. Set 인터페이스로 구현된 클래스는 HashSet, TreeSet, LinkedHashSet 이 있다.
1.2.1 HashSet
내부적으로 Map을 사용해서 구현되어 있다. 해싱(Hashing)을 이용하여 구현한 컬렉션이다. 저장 순서를 유지하려면 LinkedHashSet을 사용해야 한다.
public class HashSet<E> implements Set<E> {
private HashMap<E,Object> map;
public HashSet() {
map = new HashMap<>();
}
}HashSet은 필드로 HashMap을 가지고 있고, Set에 저장되는 데이터는 내부 HashMap의 Key 값으로 저장된다. 그리고 Map의 Value에는 의미없는 값(Dummy)이 들어가게 된다.
1.2.2 TreeSet
내부적으로 TreeMap을 사용해서 구현되어 있다. TreeMap이 근본이 되는 NavigableSet 인터페이스를 구현하고 있다. TreeSet은 이진탐색트리(BST)의 형태로 데이터를 저장한다. 그 중에서도 성능을 향상시킨 red-black tree로 구현되어 있다.
| Class | add | contains | next |
|---|---|---|---|
| HashSet | O(1) | O(1) | O(h/n) |
| LinkedHashSet | O(1) | O(1) | O(1) |
| TreeSet | O(log n) | O(log n) | O(log n) |
h: 해시 버킷의 개수, n: 해시 테이블을 사용하는 엘리먼트의 개수
[1.3 SortedSet 인터페이스]
SortedSet 인터페이스는 요소를 오름차순으로 유지하는 Set이다. TreeSet이 SortedSet으로 구현되어 있다.
[1.4 Queue 인터페이스]
Queue 인터페이스는 기본 컬렉션 작업 외에도 queue 자료구조 연산을 제공한다. LinkedList, PriorityQueue 가 Queue 인터페이스로 구현되어 있다.
[1.5 Deque 인터페이스]
Deque은 Double Ended queue의 약자이고, 양쪽 끝에 요소 삽입 및 제거를 지원한다. Deque 인터페이스로 구현된 클래스는 ArrayDeque 이 있다.
2. Map 인터페이스 그룹
[Map 인터페이스]
Map 인터페이스는 key와 value를 매핑한다. 중복 키가 존재할 수 없으며, 각 키는 하나의 값만 매핑할 수 있다. Map의 기본 연산은 다음과 같다.
- V put(K key, V value): 주어진 키와 값을 추가, 저장되면 값을 반환
- boolean containsKey(Object key): 주어진 키가 있는지 여부를 반환
- boolean containsValue(Object value): 주어진 값이 있는지 여부를 반환
- Set<Map.Entry<K, V> entrySet(): 키와 값의 쌍으로 구성된 모든 Map.Entry 객체를 Set에 담아서 반환
- V Get(Object key): 주어진 키에 매핑되는 값을 반환
- boolean isEmpty(): 컬렉션이 비어 있는지 여부를 반환
- Set
<L>keySet(): 모든 키를 Set 객체에 담아서 반환 - int size(): 저장된 키의 총 개수를 반환
- Collections values(): 저장된 모든 값을 Collection에 담아서 반환
Map 인터페이스로 구현된 클래스는 HashMap, TreeMap, LinkedHashMap 등이 있다.
2.1.1 HashMap
HashMap은 내부적으로 Entry<K, V> [] Entry Array로 구성되어 있다. 배열의 인덱스를 해시 함수를 통해 계산한다.

위 그림처럼 Entry로 저장이 되는데, 내부적으로 해시 값에 의해 어떤 버킷에 담길지 결정이 된다.
get() 메소드는 해시 값으로 해당 배열에 바로 접근이 가능하기 때문에 O(1) 의 시간 복잡도를 가진다.
2.1.2 TreeMap
TreeMap은 HashMap과 다르게 Entry가 Red-Black Tree 구조로 저장되어 있다.

위 그림처럼 트리 구조를 가지는데, 트리 구조 특성 상 특정 Entry에 접근하려면 O(log n) 성능을 보인다.
2.1.3 LinkedHashMap
큰 흐름은 HashMap과 동일하다. 하지만 Entry 내에 before, after Entry가 저장되어 있는 것이 특징이다.
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}| Class | get | containsKey | next |
|---|---|---|---|
| HashMap | O(1) | O(1) | O(h/n) |
| LinkedHashMap | O(1) | O(1) | O(1) |
| TreeMap | O(log n) | O(log n) | O(log n) |
[2.2 SortedMap 인터페이스]
SortedMap 인터페이스는 매핑을 오름차순의 키 순서로 유지하는 Map이다. TreeMap이 SortedMap 인터페이스를 받아서 구현하고 있다.
Reference
infotechgems.blogspot.com/2011/11/java-collections-performance-time.html
https://www.javatpoint.com/collections-in-java
https://soft.plusblog.co.kr/74
'Java' 카테고리의 다른 글
| [Java] String Constant Pool (1) | 2022.04.02 |
|---|---|
| [Java] Java Garbage Collection (0) | 2020.11.02 |
| [Java] Garbage Collection Algorithms (0) | 2020.10.26 |
| [Java] Immutable & Mutable (0) | 2020.10.12 |
| [Java] Java Virtual Machine (JVM) (0) | 2020.10.08 |